paperless ngx: Dein kompletter Leitfaden für ein selbstgehostetes, durchsuchbares Dokumentenmanagement
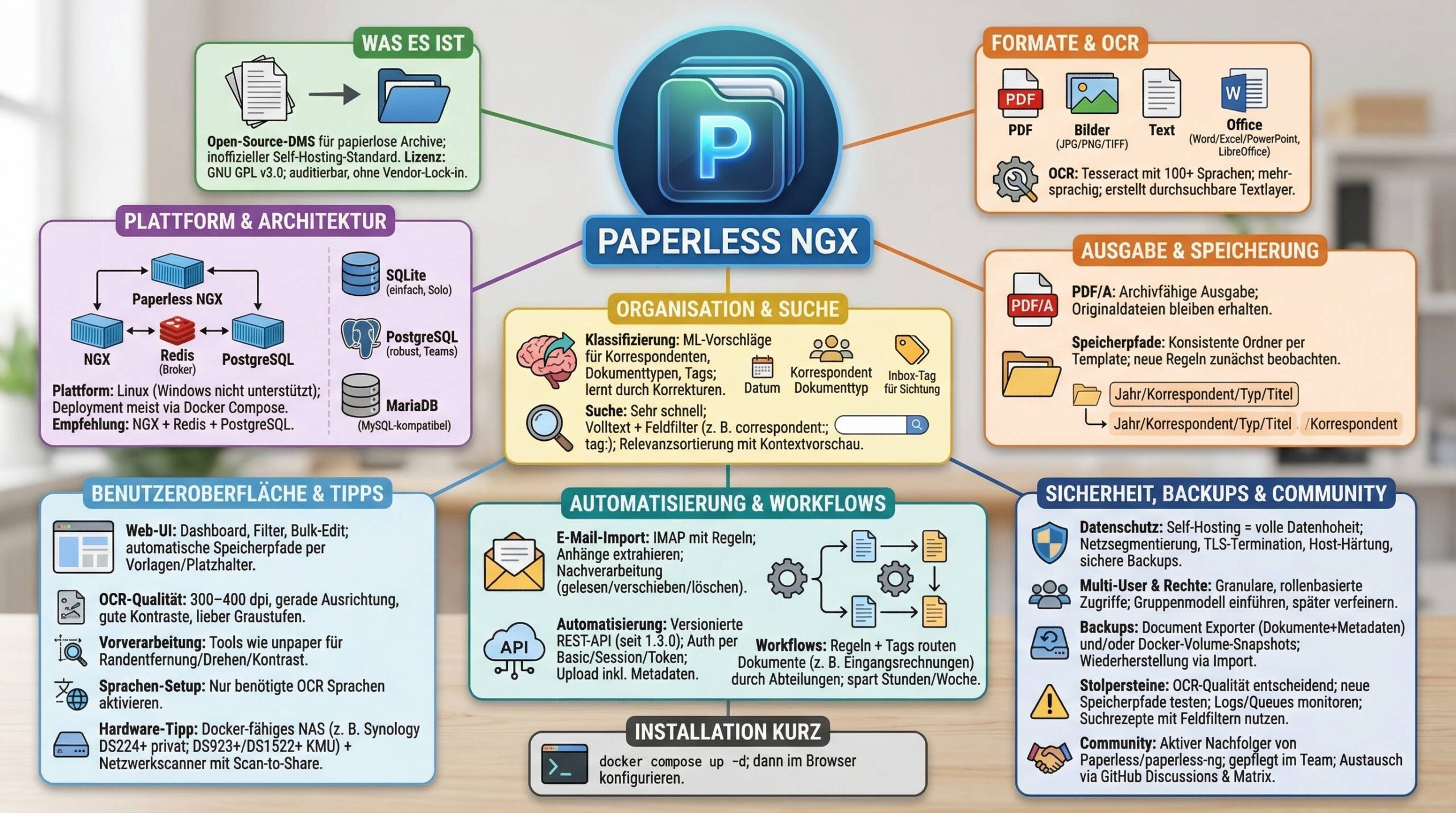
Wenn Du Deine physischen und digitalen Unterlagen in ein schnell durchsuchbares, strukturiertes und sicheres Archiv überführen willst, ist Paperless NGX eine der stärksten Open‑Source‑Optionen. Die Software kombiniert zuverlässige OCR (Texterkennung), maschinelles Lernen für die automatische Klassifizierung, ausgefeilte Metadaten, eine moderne Web-Oberfläche und eine robuste REST‑API. Das Ergebnis: ein papierloses Büro mit klaren Workflows – für Privat, Selbstständige und Teams.
- OCR out of the box: Tesseract mit Unterstützung für über 100 Sprachen, inklusive Mehrsprachigkeit.
- Automatische Klassifizierung: Tags, Korrespondenten und Dokumenttypen per Machine Learning vorschlagen lassen.
- Metadaten & Filter: Datum, Korrespondent, Dokumenttyp und Tags als zentrale Ordnungsachsen.
- PDF/A & Originale: Langzeitarchivtaugliche PDFs, Originaldateien bleiben erhalten.
- Formate: PDF, Bilder, Text, Office-Dateien (Word/Excel/PowerPoint und LibreOffice-Äquivalente).
- Suche in Echtzeit: Volltextsuche mit Feldfiltern und Relevanzbewertung.
- E-Mail-Import: IMAP-Integration mit Regeln und Nachbearbeitung (z. B. als gelesen markieren).
- API & Automatisierung: Versionierte REST‑API, Token-Auth, Integrationen und Workflows.
- Mehrbenutzer & Rechte: Granulare, rollenbasierte Zugriffskontrolle.
- Self-Hosting & Datenschutz: Volle Datenhoheit, flexible Backups, Community-getrieben.
Merke: Paperless NGX ist der inoffizielle Standard für selbstgehostete, papierlose Archive. Es ist stark genug für Unternehmen, bleibt aber intuitiv genug für Einzelanwender.
Ursprung, Lizenz und Community
Paperless NGX ist der offiziell gepflegte Nachfolger von Paperless und paperless‑ng. Das Projekt verteilte die Verantwortung bewusst auf ein Team, wodurch Weiterentwicklung, Support und Qualitätssicherung breit abgestützt sind. Es steht unter der GNU GPL v3.0: frei, quelloffen, auditierbar – mit allen Vorteilen für Datenschutz und Unabhängigkeit.
Die aktive Community organisiert sich über GitHub Discussions und einen Matrix-Chat. Spezialteams (z. B. Frontend, DevOps, CI/CD) treiben das Projekt voran, Pull Requests sind willkommen. Du profitierst so von kurzen Feedbackzyklen und einer lebendigen Roadmap – ohne Vendor-Lock-in.
Architektur und Systemvoraussetzungen
Paperless NGX läuft stabil auf Linux. Windows wird nicht unterstützt. In der Praxis setzt Du für die Installation typischerweise auf Docker (Compose), was die Einrichtung stark vereinfacht und Updates reproduzierbar macht. Für native Setups gelten Python 3.10–3.12 (neuere Versionen können funktionieren).
Datenbanken im Überblick
Du kannst zwischen SQLite (einfach), PostgreSQL oder MariaDB (skalierbarer) wählen. Für Privatanwender ist SQLite oft ausreichend; für Teams und große Archive empfiehlt sich PostgreSQL oder MariaDB.
| Option | Vorteile | Einsatzempfehlung |
|---|---|---|
| SQLite | Einfach, keine externe DB, schneller Start | Einzelanwender, kleine Archive |
| PostgreSQL | Skalierbar, robust, ausgereifte Features | Teams, große Datenbestände |
| MariaDB | MySQL‑kompatibel, weit verbreitet | Bestehende MySQL/MariaDB‑Umgebungen |
Hinweis: Für containerisierte Setups hat sich die Kombination aus Paperless NGX + Redis (Broker) + PostgreSQL bewährt.

Kernfunktionen im Detail
- OCR-Pipeline: Dokumente ohne durchsuchbaren Text werden mit Tesseract konvertiert. Ergebnis: Suchbare Textlayer in PDFs.
- PDF/A-Ausgabe + Originale: Paperless NGX erzeugt archivfähige PDF/A-Dateien und bewahrt unveränderte Originale auf.
- Formate: PDF, Bilder (z. B. JPG/PNG/TIFF), Text und gängige Office-Formate werden verarbeitet.
- Intelligente Klassifizierung: ML-Modelle schlagen Korrespondenten, Dokumenttypen und Tags vor. Deine Korrekturen „trainieren“ das System implizit.
- Dashboard & Massenbearbeitung: Moderne Web-UI mit Filtern, Statistiken, Bulk-Edit, Archivstatus auf einen Blick.
- Speicherpfade: Automatische Dateispeicherung anhand deiner Metadaten-Templates – ohne manuelles Ordnersortieren.
- Suche: Volltext plus Feldfilter (z. B. correspondent:, tag:) mit Relevanzsortierung und Treffervorschau im Kontext.
- API & Automatisierung: Vollständige REST‑API mit Basic-, Session- und Token-Auth, versioniert seit Paperless‑ngx 1.3.0.
OCR und Textverarbeitung: Qualität entscheidet
Die OCR-Funktionalität ist ein zentraler Differenziator. Damit die Texterkennung präzise arbeitet, solltest Du die Scanqualität optimieren. Schlechtes Ausgangsmaterial (niedrige Auflösung, schiefe Seiten, schwacher Kontrast) verschlechtert Ergebnisse spürbar.
- Empfohlene Scan-Parameter: 300–400 dpi, gerade Ausrichtung, gute Ausleuchtung, vorzugsweise Graustufen statt reines Schwarz/Weiß.
- Vorverarbeitung: Tools wie unpaper entfernen Ränder, drehen Seiten korrekt und erhöhen Kontraste.
- Sprachen: Setze OCR-Sprache(n) passend. Mehrsprachige Dokumente sind möglich.
Konfiguration per Umgebungsvariablen:
PAPERLESS_OCR_LANGUAGE=deu
PAPERLESS_OCR_LANGUAGES=deu+eng
Praxis-Tipp: Nutze mehrere Sprachen nur, wenn wirklich nötig. Jede zusätzliche Sprache vergrößert den Suchraum und kann die Erkennung minimal verlangsamen.
Metadaten und Organisation: Struktur ohne starre Ordnerzwänge
Paperless NGX organisiert Dokumente entlang von vier primären Dimensionen:
- Ausstellungsdatum (Erstellungs-/Dokumentdatum)
- Korrespondent (z. B. Sparkasse Düsseldorf, Versicherung A)
- Dokumenttyp (z. B. Rechnung, Vertrag, Lohnabrechnung)
- Tags (beliebig kombinierbar, z. B. Steuer, Privat, 2025)
Tags sind besonders mächtig: Ein Dokument kann mehrere Tags tragen und so auf Knopfdruck aus verschiedenen Blickwinkeln gefunden werden. Ein spezieller Tag ist die Inbox, die neuen Dokumenten automatisch zugewiesen wird – perfekt für Deinen Sichtungsprozess.
| Feld | Beispiel | Nutzen |
|---|---|---|
| Korrespondent | „Finanzamt XY“ | Quelle/Aussteller, dient der thematischen Trennung |
| Dokumenttyp | „Rechnung“, „Vertrag“ | Klassische DMS-Kategorie, unterstützt Regeln & Workflows |
| Datum | „2026-02-28“ | Zeitliche Filterung, Fristen & Jahresordnungen |
| Tags | „steuer“, „privat“, „haus“ | Flexible Mehrfachklassifikation, Suchabkürzungen |
Hinweis: Die automatische Erkennung von Korrespondenten funktioniert erstaunlich gut – oft schon nach wenigen Beispielen.

Speicherpfade und Ablagestrukturen
Statt Ordnern manuell zu pflegen, generiert Paperless NGX Ablagepfade automatisch anhand konfigurierbarer Platzhalter. So entstehen konsistente, fehlerarme Strukturen.
Beispielvorlage (vereinfachtes Prinzip):
{created:%Y}/{correspondent}/{document_type}/{title}.pdf
Daraus könnte z. B. werden:
2026/Finanzamt XY/Bescheid/Einkommensteuerbescheid 2025.pdf2025/Sparkasse Düsseldorf/Kontoauszug/Kontoauszug_03-2025.pdf
Praxis-Tipp: Auch wenn die automatische Pfadzuweisung stark ist: Prüfe neue Vorlagen ein paar Tage lang, bevor Du sie produktiv setzt. Gerade bei seltenen Dokumenttypen sind manuelle Korrekturen am Anfang normal.
Volltextsuche und Filter: Finde in Sekunden, was Du brauchst
Die Suche arbeitet praktisch in Echtzeit – ähnlich wie „Everything“ unter Windows, nur für Inhalte. Du kombinierst freie Textsuche mit Feldfiltern und bekommst Ergebnisse nach Relevanz gewichtet.
| Beispielabfrage | Erklärung |
|---|---|
stromabschlag |
Volltextsuche in allen Dokumentinhalten |
correspondent:Hochschule |
Nur Dokumente vom Korrespondenten „Hochschule …“ |
tag:steuer AND correspondent:Finanzamt |
Kombination zweier Felder – präzise Filterung |
correspondent:Hochschule AND tag:vorbereiten |
Gezielte Suche nach Kombinationen (wie im Praxisbeispiel) |
Treffer werden kontextualisiert angezeigt, sodass Du die relevanten Textstellen direkt siehst. Das spart Klicks und Zeit.
E-Mail-Integration und Automatisierung
Per IMAP holt Paperless NGX Mails aus Postfächern ab, extrahiert Anhänge und wendet Regeln an. Du kannst mehrere Konten anlegen und pro Konto Filter definieren (z. B. Absender, Betreff, Inhalt, Ordner).
- Beispiel-Regel: Alle Mails von rechnung@anbieter.de → Dokumenttyp „Rechnung“ + Tag „buchhaltung“ + Korrespondent „Anbieter GmbH“
- Nachverarbeitung: Mail als gelesen markieren, verschieben oder löschen – ganz automatisch.
Für komplexe Workflows (z. B. Extraktion strukturierter Rechnungsdaten, Validierung, Übergabe an Steuerberater) lassen sich Tools wie n8n integrieren.
Workflows und maschinelles Lernen
Das Workflow-System automatisiert Abläufe quer durch Abteilungen. Beispiel „Eingangsrechnungen“:
- Rechnung kommt per E-Mail oder Scanner in den Eingangsordner.
- Paperless NGX erkennt „Rechnung“, weist Dokumenttyp und Korrespondent zu, versieht das Dokument mit Tag „eingang“.
- Regel: Tag „eingang“ → Zuweisung an Innendienst.
- Nach Prüfung: Tag „gebucht“ → automatische Weiterleitung an Buchhaltung.
Praxisberichte zeigen, dass solche Workflows den manuellen Ablageaufwand signifikant reduzieren – teils um viele Stunden pro Woche, je nach Volumen und Teamgröße.
REST‑API: Integrierbar und skriptbar
Die API ist vollständig dokumentiert (durchsuchbar unter /api/schema/) und seit Version 1.3.0 versioniert. Authentifizierung per Basic-, Session– oder Token-Auth erlaubt saubere Integrationen in bestehende Systeme.
- Wichtige Endpunkte: Dokumente hochladen (
/api/documents/post_document/), Metadaten abfragen, Benutzer verwalten, Workflows konfigurieren. - Beim Upload: Metadaten wie Korrespondent, Dokumenttyp oder Tags kannst Du direkt mitsenden.
Beispiel: cURL-Upload mit Token
curl -X POST "https://dein-host.tld/api/documents/post_document/" \
-H "Authorization: Token <DEIN_API_TOKEN>" \
-F "document=@/pfad/zur/datei.pdf" \
-F "title=Rechnung März 2026" \
-F "correspondent=Anbieter GmbH" \
-F "document_type=Rechnung" \
-F "tags=buchhaltung,maerz"
Tipp: Nutze die API für Massenimporte, für die Synchronisation aus Drittsystemen oder für individuelle Dashboards.
Benutzerrechte und Multi-User-Unterstützung
Über rollenbasierte Zugriffssteuerung legst Du fest, wer was sehen, bearbeiten oder löschen darf – bis hinunter auf Objektebene (Dokumente, Tags, Dokumenttypen, Speicherpfade). Für Teams empfiehlt sich ein Gruppenmodell:
- Gruppen nach Bereich: Innendienst, Buchhaltung, HR, Management
- Berechtigungen je Gruppe: Leserechte für relevante Dokumenttypen, Schreibrechte nur dort, wo nötig
- Transparenz: Dokumentiertes Berechtigungskonzept, schrittweise Einführung, regelmäßige Reviews
Datenschutz und Sicherheit
Die größte Stärke des Self-Hostings: Deine Daten bleiben lokal. Du bestimmst Speicherort, Backup-Rhythmus, Netzwerkgrenzen und Zugriff. Für viele Anwendungsfälle ist das ein wesentlicher Compliance‑Baustein.
Wenn Du eine kommerzielle Variante wählst, können zusätzliche Sicherheitsfeatures wie Single Sign‑On, SCIM‑User‑Provisioning oder erweiterte Protokollierung verfügbar sein. Im Self‑Hosting stehen saubere Netzsegmentierung, TLS‑Terminations, Härtung des Host-Systems sowie sichere Backups im Vordergrund.
Installation per Docker Compose: Schritt für Schritt
Nachfolgend ein praxistaugliches Grundsetup mit Redis und PostgreSQL. Passe Hostpfade, Passwörter, Ports und Domains an Deine Umgebung an.
version: "3.8"
services:
broker:
image: redis:alpine
restart: unless-stopped
db:
image: postgres:15
environment:
- POSTGRES_DB=paperless
- POSTGRES_USER=paperless
- POSTGRES_PASSWORD=dein_db_passwort
volumes:
- ./db:/var/lib/postgresql/data
restart: unless-stopped
webserver:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
depends_on:
- db
- broker
ports:
- "8000:8000"
environment:
- PAPERLESS_REDIS=redis://broker:6379
- PAPERLESS_DBHOST=db
- PAPERLESS_DBNAME=paperless
- PAPERLESS_DBUSER=paperless
- PAPERLESS_DBPASS=dein_db_passwort
- PAPERLESS_OCR_LANGUAGE=deu
- PAPERLESS_OCR_LANGUAGES=deu+eng
- PAPERLESS_TIME_ZONE=Europe/Berlin
- PAPERLESS_URL=http://localhost:8000
- PAPERLESS_ADMIN_USER=admin
- PAPERLESS_ADMIN_PASSWORD=ein_sicheres_passwort
volumes:
- ./data:/usr/src/paperless/data
- ./media:/usr/src/paperless/media
- ./consume:/usr/src/paperless/consume
restart: unless-stopped
- Start:
docker compose up -d - Zugriff: Browser →
http://localhost:8000(oder Deine Domain) - Erste Schritte: Anmelden, Benutzer anlegen, OCR-Sprachen prüfen, E-Mail-Konten und Regeln konfigurieren
Hinweis: Office-Dateikonvertierung kann je nach Setup zusätzliche Komponenten benötigen. Prüfe die Projektdokumentation, wenn Du viele Office-Formate verarbeiten möchtest.
Hardware-Empfehlungen: NAS + Netzwerkscanner
Ein schlankes, robustes Setup für den Dauerbetrieb besteht aus einem NAS (als zentralem Speicher und Container-Host) plus Netzwerkscanner (Scan-to-Share/Scan-to-FTP in den „consume“-Ordner).
| Komponente | Empfehlung | Einsatz | Vorteile |
|---|---|---|---|
| NAS (Privat) | Synology DS224+ | 1–2 Benutzer | Docker‑fähig, leise, genügende Leistung |
| NAS (KMU) | Synology DS923+ / DS1522+ | Mehrere Benutzer, mehr Speicher | Mehr RAM/CPU, Skalierbarkeit, Docker-Umgebung |
| Netzwerkscanner | Epson WorkForce ES‑580W o. ä. | Scan direkt ins Archiv | Hohe Durchsatzraten, zuverlässiges Scan‑to‑Share |
Vorteil: Der Scanner wirft Dokumente direkt in den Verarbeitungsordner des NAS. Paperless NGX nimmt sie automatisch auf – keine PC-Zwischenstation nötig.
Backup und Wiederherstellung
Backups sind Pflicht. Du hast mehrere Optionen:
- Document Exporter: Exportiert Dokumente, Miniaturen, Metadaten und Datenbankinhalte in einen strukturierten Ordner. Lässt sich später importieren oder in ein anderes DMS überführen.
- Docker-Volume-Backups: Sicherung der Volumes (z. B. unter
/var/lib/docker/volumes) via Snapshot/rsync.
Wiederherstellung:
- Leere Paperless-Instanz bereitstellen (kompatible Version verwenden).
- Mit dem Document Importer den Export wieder einspielen.
Wichtig: Exporte sind exakte Abbilder. Exporte von einer Version lassen sich nicht beliebig in andere Versionen importieren, wenn sich die Datenbankstruktur geändert hat. Plane Updates und Backups deshalb koordiniert.
Praxis-Tipps und bekannte Stolpersteine
- OCR-Qualität ist Schlüssel: Investiere in saubere Scans. 300–400 dpi und gute Vorverarbeitung erhöhen die Trefferquote drastisch.
- Automatische Speicherpfade: Sehr nützlich, aber bei exotischen Dokumenten nicht unfehlbar. Beobachte neue Regeln zunächst aufmerksam.
- Klassifikationsmodelle brauchen Beispiele: Je mehr (und je konsistenter) Du korrigierst, desto besser werden die Vorschläge.
- Mehrbenutzer-Konfiguration: Nicht zu fein granular starten. Lieber mit Gruppen arbeiten und Berechtigungen später schärfen.
- Suche clever nutzen: Feldfilter sind mächtig. Baue Dir „Suchrezepte“ für wiederkehrende Aufgaben (z. B. tag:steuer AND year:2025 – falls Du Jahres-Tags nutzt).
- Monitoring: Logs im Blick behalten, besonders während der Anfangsphase und bei großen Importen.
Fazit
Paperless NGX ist ein ausgereiftes, performantes und flexibles Open‑Source‑DMS, das sich nahtlos auf Linux per Docker betreiben lässt. Dank starker OCR, intelligenter Klassifizierung, durchdachten Metadaten und einer kraftvollen Suche bringst Du Ordnung in große und heterogene Dokumentbestände – mit echter Zeitersparnis im Alltag. E‑Mail‑Import, REST‑API, Mehrbenutzerrechte und automatisierte Workflows runden das Bild ab. Kurz: Wenn Du ein selbstgehostetes, zukunftssicheres Dokumentenmanagement suchst, bekommst Du mit Paperless NGX genau das richtige Werkzeug – ohne Abhängigkeit von proprietären Anbietern und mit voller Datenhoheit.
FAQ
Unterstützt Paperless NGX Windows?
Nein. Paperless NGX läuft offiziell auf Linux. Für produktive Umgebungen empfiehlt sich ein Linux‑Host mit Docker. NAS-Systeme mit Container-Unterstützung sind ebenfalls geeignet.
Welche OCR-Sprachen kann ich nutzen?
Über Tesseract stehen mehr als 100 Sprachen zur Verfügung. Konfiguriere die Sprache(n) per PAPERLESS_OCR_LANGUAGE und PAPERLESS_OCR_LANGUAGES. Nutze nur die wirklich benötigten Sprachen, um die Erkennung zu optimieren.
Wie gut funktioniert die automatische Klassifizierung?
Erstaunlich gut – besonders bei Korrespondenten. Die Genauigkeit steigt, je mehr Beispiele Du im System hast und je konsequenter Du Vorschläge bestätigst oder korrigierst.
Kann ich Office-Dokumente (Word/Excel/PowerPoint) verarbeiten?
Ja. Paperless NGX unterstützt gängige Office-Formate sowie deren LibreOffice‑Äquivalente. Je nach Setup können zusätzliche Konverterkomponenten notwendig sein – prüfe die Projektdokumentation, falls Du viele Office-Dateien importierst.
Wie funktioniert die E-Mail-Integration?
Du hinterlegst IMAP-Konten, definierst Regeln (z. B. nach Absender/Betreff/Ordner) und legst fest, wie Paperless NGX mit der Mail nach dem Import umgeht (z. B. als gelesen markieren oder löschen). Anhänge werden extrahiert und in den Verarbeitungsworkflow übernommen.
Wie richte ich Backups ein?
Variante 1: Nutze den Document Exporter, um Dokumente, Thumbnails und Metadaten strukturiert zu sichern. Variante 2: Sichere Docker-Volumes per Snapshot/rsync. Wichtig: Exporte sind versionsgebunden, plane Updates und Wiederherstellungen entsprechend.
Ist die Suche wirklich „in Echtzeit“?
Ja, die Volltextsuche ist sehr schnell. In Kombination mit Feldfiltern (z. B. correspondent:, tag:) findest Du auch in großen Archiven gewünschte Dokumente in Sekunden.
Wie skaliere ich für Teams?
Setze auf PostgreSQL/MariaDB, ausreichend CPU/RAM und saubere Gruppenkonzepte für Rechte. Überwache Importlast und OCR‑Warteschlangen, verteile Jobs zeitlich (z. B. Nachtscans).
Gibt es eine API?
Ja. Die REST‑API ist ausführlich dokumentiert (unter /api/schema/). Unterstützte Authentifizierungen sind Basic‑Auth, Session‑Auth und Token‑Auth. Du kannst Dokumente hochladen, Metadaten pflegen, Benutzer verwalten und Workflows automatisieren.
Welche Hardware ist empfehlenswert?
Für Privatanwender: ein Docker‑fähiges NAS wie die Synology DS224+. Für kleine Unternehmen: DS923+ oder DS1522+. Als Netzwerkscanner eignen sich Modelle mit zuverlässigem Scan‑to‑Share, z. B. Epson WorkForce ES‑580W. Das Ziel: Scanner → NAS‑Ordner → automatische Verarbeitung durch Paperless NGX.
Kann ich die Ordnerstruktur selbst definieren?
Ja. Über Platzhalter generiert Paperless NGX Speicherpfade automatisch (z. B. nach Datum/Korrespondent/Dokumenttyp/Titel). Das spart manuelle Arbeit und sorgt für einheitliche Strukturen.
Wie gehe ich mit schlechter OCR-Qualität um?
Verbessere die Scanqualität (300–400 dpi, gerade Ausrichtung, gute Kontraste) und nutze Vorverarbeitungstools wie unpaper. Setze die OCR-Sprachen passend, vermeide unnötige Mehrsprachigkeit.